
تشخیص و پیشبینی اختلال خونی و سرطان با استفاده از هوش مصنوعی (شبکههای عصبی مصنوعی)
چکیده:
این مقاله یک استفاده نوآورانه از شبکههای عصبی مصنوعی در علم پزشکی را نشان میدهد. تکنیک پیشنهادی شامل آموزش پرسپترون چند لایه (MLP))یک نوع شبکه عصبی مصنوعی) با الگوریتم یادگیری BP برای تشخیص الگو برای تشخیص و پیشبینی پنج اختلال خونی است، از طریق نتایج آزمایش های خون از دستگاه H1 است. پارامترهای آزمایش خون و تشخیص پزشک درباره بیماریهای ۴۵۰ بیمار از بیمارستان طالقانی در کرمانشاه ایران، در یک روش آموزش نظارت شده برای بهروز رسانی پارامترهای شبکه استفاده میشود. این روش برای تشخیص این اختلال و سرطان پیادهسازی شده است: کم خونی مگالوبلاستیک، تالاسمی، پورپورای ترومبوسیتوپنیک ایدئوپاتیک (ITP)، لوسمی مزمن میلوژنوس و لنفوپرولیفراتیو.
مقدمه
یکی از مسائل اساسی در پزشکی، تشخیص بیماری است. بسیاری از برنامهها برای کمک به متخصصان در ارائه یک راه حل امتحان شدهاند. این مقاله توضیح میدهد که چگونه هوش مصنوعی، به عنوان مثال شبکههای عصبی مصنوعی، میتوانند این حوزه تشخیص را بهبود بخشند. به طور متوسط، بدن انسان حاوی پنج لیتر خون است و سلولهای قرمز خون شما هر ۱۲۰ روز یکبار جایگزین میشوند. بیماریهای خون میتوانند از کم خونی که شایع است تا اختلالات نادر که فقط چند نفر را تحت تأثیر قرار میدهد، متفاوت باشند. بسیاری از بیماریهای مختلف بر روی خون تأثیر میگذارند. بسیاری از افراد به نوعی از بیماری خونی مبتلا هستند، چه تشخیص داده شده یا نه. در ایالات متحده آمریکا، تقریباً ۷۲،۰۰۰ نفر دچار کم خونی سلول داسی شکل با حدود ۲،۰۰۰،۰۰۰ نفر حامل ویژگی هستند. در آمریکا، ۲۰،۰۰۰ بیمار هموفیلی وجود دارد. هر سال، تقریباً ۲۷،۰۰۰ نفر بزرگسال و بیش از ۲،۰۰۰ کودک در ایالات متحده آمریکا متوجه می شوند که به سرطان خون مبتلا هستند (آمار از وب سایت NIH و Cancernet است).
سلامت یک جمعیت، که اساساً مبتنی بر نتایج تحقیقات پزشکی است، تأثیر زیادی بر تمام فعالیتهای انسانی دارد. اختلالات خونی یکی از شاخههای مهم پزشکی داخلی است. با پیشرفت سریعی که در سالهای اخیر در این حوزه انجام شده است، ما فکر میکنیم که نیاز به توجه ویژه به بهبود روشهای مرسوم وجود دارد. با این پیشینه، ما یک ایده جدید در تشخیص اختلالات گسترده ارائه کردهایم.
ما میدانیم که در علوم پزشکی، تفسیر صحیح دادهها و ارائه تشخیص درست و زودهنگام بسیار مهم است. اینها میتوانند پایهای برای درمان خوب و مؤثر به ویژه در هماتولوژی باشند، همانطور که در سایر حوزههای اختلالات پزشکی داخلی نیز است. تصمیمگیری پزشکی به علت عدم توانایی کارشناسان در پردازش حجم عظیم دادهها، فعالیتی بسیار دشوار است. پزشکان معمولاً از عدم وجود تحلیل خوب و دقیق این دادههای آزمایشگاهی رنج میبرند. آنها به یک ابزار نیاز دارند که به آنها در تصمیمگیری خوب کمک کند. یک سیستم خبره یا شبکههای عصبی مصنوعی، که بخشی از هوش مصنوعی هستند، بسیار مفید خواهند بود.
با توجه به این دیدگاه و استفاده از آن به عنوان یک سیستم مرجع خوب در تصمیمگیری برای بیماران، ما یک روش جدید با قدرت تحلیلی با کیفیت (و کمیت) بالا ارائه دادهایم که این مشکلات را حل میکند.
به همین دلیل تعداد متخصصان خون (پزشکان متخصص در هماتولوژی؛ هماتولوژی: شاخهای از زیستشناسی، پاتولوژی، آزمایشگاه بالینی، پزشکی داخلی و پزشکی کودکان است که به مطالعه خون، اندام های خون ساز و بیماریهای خون میپردازد. هماتولوژی شامل مطالعه علتشناسی، تشخیص، درمان، پیشبینی و پیشگیری از بیماریهای خون است. کارهای آزمایشگاهی که به مطالعه خون می پردازد توسط تکنسین پزشکی انجام می شود) محدود است و در بیشتر شهرهای کوچک و کلینیکهای، هیچ پزشکی وجود ندارد. بنابراین، این روش میتواند بسیار مفید باشد و در هر بیمارستان عمومی، کلینیک و حتی آزمایشگاه برای تشخیص اولیه استفاده شود و برای متخصصان خون ارسال شود.
در ابتدا، ما به دنبال تشخیص و پیشبینی اختلال با شبکه عصبی مصنوعی بودیم. ما دریافتیم که حداکثر تحقیقات و راه حل ها در شاخه پزشکی معمولاً به طور کامل انجام نمی شود. برای مثال، بیشتر شبکههای عصبی مصنوعی در تشخیص این اختلالات استفاده میشوند: سرطان سینه [به یک دیدگاه یکپارچه از پیادهسازی سیستمهای تشخیصی خودکار برای تشخیص سرطان سینه وجود دارد]، سرطان پروستات (با استفاده از روش توسعهیافته بیوپسی)، آنها مدلهای چند متغیرهای را برای پیشبینی سرطان پروستات با بیوپسی اولیه ایجاد و اعتبارسنجی کردند و بررسی کردند که آیا این مدلهای مبتنی بر بیوپسی توسعهیافته و یک مدل شبکه عصبی که با رگرسیون لجستیک برای پیشبینی این سرطان مقایسه میشود، یا خیر، بیماری قلبی مانند بیماری عروق کرونر، یا برای طبقه بندی بیماری های قلبی، بیماری آلزایمر، بیماری مغز، مانند یک سیستم زیست پزشکی مبتنی بر مدل های فازی و مارکوف پنهان گسسته برای تشخیص بیماری های مغز، سرطان دهانه رحم، تشخیص دارماتولوژی به منظور بهبود تشخیص، دیابت مانند پیش بینی پیشرفت نفروپاتی دیابتی، بیماری عصب نوروژل، سرطان تخمدان، پانکراتیت و سرطان پانکراس.
طرح کلی این مقاله به شرح زیر است: در بخش ۲، جزئیات روش شبکههای عصبی مصنوعی بررسی شده و ساختار استفاده شده توضیح داده شده است. بخش ۳ نتایج عددی ما برای موارد مختلف شبکههای عصبی مصنوعی طراحی شده را ارائه میدهد. بخش ۴ روشهای مرسوم را به منظور مقایسه عملکرد ANN برای پیشبینی اختلالات فوق الذکر با روشهای کلاسیک مانند راه حلهای آماری، روش رگرسیون چندمتغیره غیر خطی (با نرمافزار SPSS V.13) ارائه میدهد. نتایج این روش به طور کامل در این بخش ارائه شده است. آخرین بخش مقایسه نتایج این دو روش را برای نشان دادن کارایی شبکههای عصبی، همگرایی سریع و استفاده کم از حافظه در هر نوع تشخیص اختلال توضیح میدهد.
روش شبکههای عصبی:
شبکههای عصبی از عناصر پردازش ساده و متصل به هم به نام نورون ها تشکیل شده اند که به صورت موازی عمل میکنند. این عناصر توسط سیستمهای عصبی بیولوژیکی فعال میشوند. همانند طبیعت، عملکرد شبکه به طور قابل توجهی توسط اتصالات بین عناصر تعیین میشود. ما میتوانیم یک شبکه عصبی را برای انجام یک تابع خاص با تنظیم مقادیر اتصالات (وزنها) بین عناصر برنامهریزی کنیم.
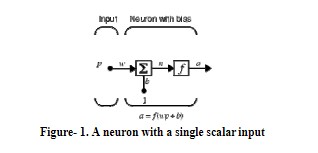
یک نورون مصنوعی نمایش سادهای است که با استفاده از معادلات ریاضی، یکپارچه سازی سیگنال و رفتار شلیک آستانه نورون های بیولوژیکی را شبیهسازی میکند. همانند نمونههای زیستی خود، نورون های مصنوعی را می توان با اتصالاتی که جریان اطلاعات بین نورون های همتا را تعیین می کند، به هم متصل کرد. استیمولها از یک عنصر پردازش به عنصر دیگر از طریق سیناپسها یا اتصالات میانی منتقل میشوند که ممکن است تحریککننده یا مهارکننده باشند. اگر ورودی به یک نورون تحریککننده باشد، احتمالاً این نورون سیگنال تحریککننده را به سایر نورونهای متصل به آن منتقل خواهد کرد. در حالی که ورودی مهارکننده احتمالاً به صورت مهارکننده منتشر خواهد شد. یک نورون با یک ورودی عدد صحیح در شکل -۱ نشان داده شده است.
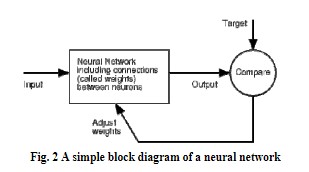
معمولاً شبکههای عصبی به گونهای تنظیم یا برنامهریزی میشوند که ورودی خاصی به خروجی هدف خاصی منتهی شود. در اینجا، شبکه بر اساس مقایسه خروجی و هدف، تنظیم میشود تا خروجی شبکه با هدف همخوانی داشته باشد. به طور معمول، تعداد زیادی از این جفت های ورودی/هدف برای برنامه ریزی یک شبکه مورد نیاز است. یک بلوک دیاگرام ساده از یک شبکه عصبی در شکل -۲ نشان داده شده است.
توابع پیچیده در حوزههای مختلف، از جمله تشخیص الگو، شناسایی، طبقهبندی، گفتار، بینایی و سیستمهای کنترل، با استفاده از شبکههای عصبی برنامهریزی شدهاند. امروزه شبکه های عصبی را می توان برای حل مسائلی برنامه ریزی کرد که برای کامپیوترهای معمولی یا انسان ها دشوار است. یک شبکه عصبی در برازش توابع و شناسایی الگو بسیار برتر است. در واقع، شواهدی وجود دارد که نشان میدهد یک شبکه عصبی نسبتاً ساده میتواند برای هر عملکرد عملی مناسب باشد.
شبکههای MLP:
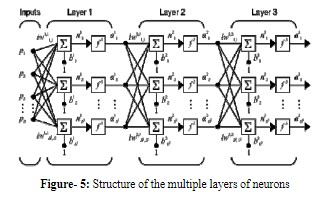
برای کاربردهای مختلف از انواع مختلفی از شبکههای عصبی استفاده میشود. MLPها به عنوان سادهترین و بنابراین بیشترین استفاده شونده، به دلیل انعطاف پذیری ساختاری، قابلیت نمایش خوب و دسترسی به تعداد زیادی الگوریتم برنامهریزی استفاده میشوند. MLPها شبکههای عصبی feed forward و تقریبدهندههای یکنواخت هستند که با الگوریتم back propagation استاندارد برنامهریزی میشوند. آنها شبکههای نظارت شده هستند، بنابراین نیاز به پاسخ مطلوب برای آموزش دارند. آنها قادر به تبدیل دادههای ورودی به پاسخ مطلوب هستند، بنابراین به طور گسترده برای طبقه بندی الگوها استفاده می شوند. با یک یا دو لایه پنهان، آنها می توانند تقریباً هر نگاشت ورودی-خروجی را تقریب بزنند. یک MLP شامل سه لایه است: لایه ورودی، لایه خروجی و لایه میانی یا پنهان. در این شبکه، هر نورون به همه نورونهای لایه بعدی متصل است، به عبارت دیگر، یک MLP یک شبکه کاملاً متصل است. شکل-۳ ساختار یک MLP را نشان میدهد.
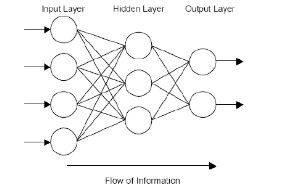
عناصر پردازش (PE) یا نورونها در لایه ورودی فقط به عنوان بافری برای توزیع سیگنالهای ورودی xi (i نشاندهنده PE ورودی i ام) به PEs در لایه پنهان عمل میکنند. هر PE j (j نشاندهنده j-امین PE در لایه پنهان و لایه خروجی) در لایه پنهان مقادیر وزندهی شده اتصالات مربوطه wji از لایه ورودی را محاسبه کرده و سیگنالهای ورودی xi خود را محاسبه میکند و خروجی yj خود را به عنوان تابع f از مجموع محاسبه میکند، به شکل زیر:
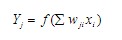
برای تابع انتقال f، انتخابهای مختلفی وجود دارد که میتواند به صورت سراسری پشتیبانی شود. تنها محدودیت این تابع این است که باید قابل مشتق باشد (شکل-۴).
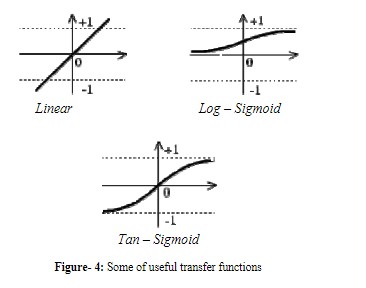
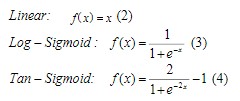
خروجی عناصر پردازش در لایه خروجی به طور مشابه محاسبه می شود. ساختار لایه های چندگانه نورون ها را می توان در شکل زیر مشاهده کرد
برنامهریزی شبکه:
قبل از برنامهریزی یک شبکه feed forward، باید وزنها و بایاسها مقداردهی اولیه شوند. پس از مقداردهی اولیه وزنها و بایاسها، شبکه آماده برنامهریزی است. برنامهریزی یک شبکه شامل تنظیم وزنهای آن با استفاده از یک الگوریتم برنامهریزی است. فرآیند برنامهریزی نیازمند یک مجموعه نمونه از پاسخ مناسب شبکه، ورودی شبکه و خروجی هدف است.
در طول برنامهنویسی، وزنها و بایاسهای شبکه به طور مکرر تنظیم میشوند تا عملکرد عملکرد شبکه را به حداقل برسانند.
MLP مورد استفاده در این کار با یک الگوریتم قابل برنامه ریزی پس انتشار (BP) برنامه ریزی شده است. این الگوریتم برنامه نویسی با تلاش برای به حداقل رساندن مجموع اختلاف مجذور بین مقادیر مطلوب و واقعی نورون های خروجی، وزن ها را بهینه می کند.
نرمافزارهای ANN موجود امروزه، ساختارهای شبکه عصبی و الگوریتمهای قابل برنامهریزی زیادی را فراهم میکنند و همچنین به کاربران کمک میکنند تا به راحتی ANN را برای مسائل خاص خودشان اعمال کنند. ابزار Neural-Network Toolbox شرکت MATLABTM ممکن است نمونه خوبی از این نرمافزارها باشد. همچنین، میتوان با استفاده از کامپایلرهای موجود، نرمافزار ANN را نوشت.
کاربرد ANN در تشخیص و پیشبینی اختلالات خونی و سرطان:
در این مقاله، با استفاده از شبکه عصبی MLP، یک روش قابل اجرا برای تشخیص و پیشبینی پنج بیماری خون و سرطان از طریق نتایج آزمایشهای خون، ارائه شده است. برای برنامهنویسی و آزمایش شبکه، ۴۵۰ سری داده که از آزمایش خون ۴۵۰ بیمار که توسط متخصصان خون بررسی شده بودند، استفاده شد. در این آزمایشهای خونی، یازده پارامتر که در تشخیص این اختلالات نقش دارند، استفاده شدهاند. این پارامترها به عنوان ورودی شبکه استفاده شدهاند. پارامترهای ورودی شامل گلبول های سفید خون (WBC)، گلبول های قرمز خون (RBC)، هموگلوبین (HGB)، حجم متوسط گروه خونی (MCV)، هموگلوبین متوسط گروه خونی (MCH)، غلظت هموگلوبین متوسط گروه خونی (MCHC)، عرض توزیع سلول قرمز (RDW)، پلاکت (PLT)، نوتروفیل (NEUT)، لنفوسیت و لکوسیت (LUC) [پارامترهای نتایج آزمایشهای خونی] است. خروجی آن پنج بیماری خونی است: کمخونی مگالوبلاستیک، آلفا-تالاسمی، پورپورا ترومبوسیتوپنیک ایدیوپاتیک (ITP)، لوسمی مزمن نخاعی و لنفوپرولیفراتیو.
برای ارائه مسئله به صورت ریاضی، یک شبکه پرسپترون چندلایه با یازده داده ورودی و پنج داده خروجی ایجاد شده است. این شبکه شامل سه لایه است (لایه ورودی، لایه پنهان و لایه خروجی). تعداد نورونها در لایه ورودی برابر با تعداد متغیرهای ورودی (یازده) است و تعداد نورون در لایه خروجی برابر با تعداد دادههای خروجی (پنج) است. این شبکه با جعبه ابزار شبکه عصبی MATLAB، با استفاده از ۳۶۰ سری از ۴۵۰ سری داده در دسترس شبیه سازی شده بود که برای برنامهنویسی شبکه و ۹۰ سری برای آزمایش آن استفاده شده است.
با توجه به خروجی شبکه، همواره دو مقدار ۰ و ۱ وجود دارد. تابع انتقال log-sigmoid برای لایه خروجی انتخاب شده است. برای دستیابی به بهترین تابع انتقال برای لایه ورودی و لایه پنهان، چندین آزمایش انجام شد. بهترین نتیجه با استفاده از یک شبکه با استفاده از تابع انتقال tan-sigmoid در هر دو لایه ورودی و پنهان به دست آمد. برای تعداد نورونها در لایه پنهان، گزینههای زیادی وجود دارد. به منظور دستیابی به بهترین شبکه با پارامترهای بهینه، مقایسهای بین شبکهها با تعداد نورونهای مختلف در لایه پنهان انجام شده است.
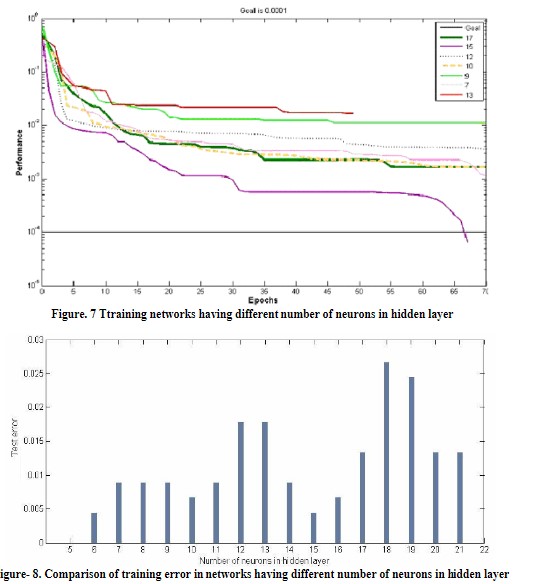
بهترین نتیجه برای این مسئله به دست آمد (که باید به خاطر داشت که افزایش تعداد نورونها در لایههای پنهان ممکن است باعث بروز مشکل بیشبرازش در شبکه شود. برای جلوگیری از این مشکل، تعداد نورونها باید کمتر از موارد موجود در الگوریتم برنامهنویسی باشد). باید گفت که در مورد این مسئله، مقدار خطای تست مهمتر از تعداد وقوع است، بنابراین مقدار خطای تست، راهنمای اصلی مورد استفاده در تصمیمگیری بود.
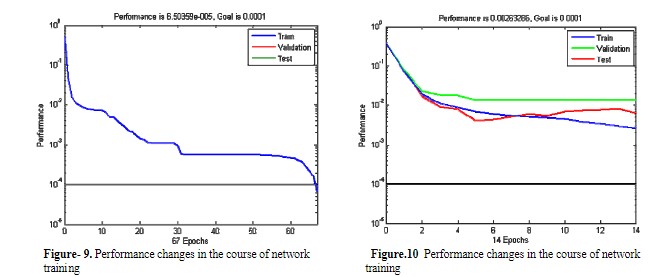
هنگامی که شبکه بیش از حد برنامهنویسی شود (بیشبرازش)، تعمیم پذیری خوبی ندارد. استفاده از اعتبارسنجی (cross-validation) یک معیار بسیار توصیه شده برای پایان دادن به برنامه نویسی یک شبکه است. هنگامی که خطا در اعتبارسنجی افزایش مییابد، باید برنامهنویسی متوقف شود. روش عملی برای یافتن یک دید کلی استفاده از یک درصد کوچک (حدود ۱۰٪) از مجموعه برنامهنویسی برای اعتبارسنجی است.
برای به دست آوردن یک دید کلی بهتر از شبکههای ارائه شده در این کار، ۹۰ سری از دادههای برنامهنویسی (که به صورت تصادفی انتخاب شده بودند) به عنوان مجموعههای اعتبارسنجی مورد استفاده قرار گرفتند.
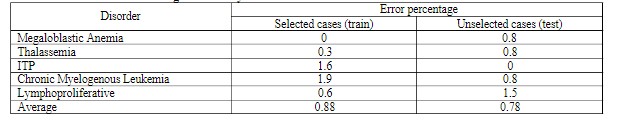
روش سنتی: به منظور نشان دادن قابلیت، دقت و توانایی کاربردهای شبکه عصبی مصنوعی در پیشبینی بیماریها، ما روش شبکه عصبی را با یکی از روشهای سنتی که به طور مشابه این کار را انجام میدهد، مقایسه کردیم. یکی از این روشهای سنتی استفاده از روشهای آماری است. روش آماری که ما استفاده کردیم، روش رگرسیون غیرخطی چند متغیره بود تا رابطهای بین هر بیماری و دادههای ورودی برای تجزیه و تحلیل موارد پیدا کند و همچنین بر اساس این روابط، برای موارد جدید پیشبینی بیماری انجام دهد. با استفاده از این روش، تمام ۴۵۰ مورد به صورت تصادفی به دو مجموعه تقسیم شدند که شامل موارد انتخاب شده برای تجزیه و تحلیل و موارد انتخاب نشده بودند.
نتایج نهایی تحلیلهای رگرسیون برای خروجی و میانگین این پنج بیماری در جدول زیر نشان داده شده است. برای مقایسه دقت این روش با روش شبکه عصبی، باید یک شاخص خطای میانگین از تمام دادههای خروجی داشته باشیم، زیرا روش شبکه عصبی همه پنج خطای خروجی را به صورت همزمان شبیهسازی و محاسبه میکند. از این نتایج میتوانیم این دو روش را مقایسه کنیم.
نتیجهگیری:
اولین موضوعی که باید مورد بحث قرار گیرد داده هایی است که برای برنامه ریزی و آزمایش شبکه MLP نمونه برداری شده است. داده ها از نتایج آزمایش خون ۴۵۰ بیمار که توسط هماتولوژیست ها در بیمارستان طالقانی کرمانشاه معاینه شده بودند، جمع آوری شد. نمونه داده ها برای آموزش، اعتبارسنجی و آزمون شبکه عصبی (نسبت ۶۰-۲۰-۲۰ برای آموزش با اعتبارسنجی و نسبت ۸۰-۲۰ برای آموزش بدون آن) و همچنین برای تحلیل رگرسیون غیرخطی چند متغیره (نسبت ۷۰-۳۰) استفاده شد. تعداد لایههای پنهان و نورونها در هر لایه از طریق آزمون و خطا تعیین شد تا بهینه شود، از جمله با استفاده از توابع انتقال مختلف مانند تانژانت-سیگموئید و لگاریتم-سیگموئید. پس از چندین آزمایش، بهترین نتیجه از یک شبکه سه لایه به دست آمد. در این شبکه، تابع تانژانت-سیگموئید در لایه ورودی و پنهان و تابع لگاریتم-سیگموئید در لایه خروجی استفاده میشود و مناسب ترین پیکربندی شبکه یافت شده ۱۱×۱۵×۵ بود. این بدان معناست که تعداد نورونها برای لایه پنهان برابر با ۱۵ است. برای آموزش شبکه با الگوریتم یادگیری backpropagation، تابع عملکرد MSE با مقدار هدف ۰٫۰۰۰۱ و تابع trainlm استفاده شد و روش cross-validation برای متوقف کردن آموزش استفاده شد تا مشکل بیشبرازش را جلوگیری کند. از نتایج به دست آمده در دو فصل آخر، شبکه عصبی طراحی شده دارای ۰٫۳۳۳۳ درصد خطا است، در حالی که تحلیل SPSS دارای ۰٫۷۸ درصد خطا است. با توجه به این نتایج، میتوان نتیجه گرفت که شبکه عصبی مصنوعی به دلیل دقت بالا، همگرایی سریع و استفاده کم از حافظه برای تشخیص و پیشبینی اختلالات، کاربرد دارد. یک ویژگی برجسته دیگر این شبکه، قابلیت تشخیص همزمان تمام پنج اختلال مذکور است که در عین حال، رگرسیون غیرخطی چند متغیره تنها برای یک اختلال در هر زمان قابل تحلیل است.
تدوین و ترجمه: لیلا قدیری کارشناس هوش مصنوعی و آموزش الکترونیک
منبع: researchgate.net
نظر شما :